Business School, Web scrapes, and Machine Learning.
As a prospective MBA applicant, you're likely only interested in profiles similar to your own. Yet, its unlikely that someone has your exact stats and background, so you go for the closest approximation... but there are hundreds of these profiles and they're spread across ~60 different articles.


Poets & Quants is one of the most popular sites around for prospective MBA students.
| Global Popularity Rank | |
|---|---|
| poetsandquants.com | 88,669 |
| mbacrystalball.com | 97,595 |
| veritasprep.com | 122,750 |
| beatthegmat.com | 197,316 |
| topmba.com | 220,956 |
| clearadmit.com | 289,200 |
| fortunaadmissions.com | 2,370,468 |
One of their particularly anxiety inducing article segments is titled Handicapping Your Elite MBA Odds. In each of these articles, Sanford “Sandy” Kreisberg, founder of MBA admissions consulting firm HBSGuru, goes through user-submitted profiles and gives them his expert opinion on their chances of getting into particular MBA programs.
The submitted profiles typically include information like this:
- GMAT or GRE score
- GPA
- Major & School
- Work Experience & Industry
- Extracurriculars or Goals
- Race, Age, Gender
The Problem
As a prospective MBA applicant, you're likely really just interested in the profile that is a closest match to your own- but, it's unlikely that someone has the exact same stats and background, so you settle for the closest approximation. The issue is that there are hundreds of these profiles and they're spread across over 60 distinct articles.
If you look at the comment section in these articles, you'll see that the readers of the site are always asking for their particular profile to be featured. But, TMZ Poets & Quants can't possibly accommodate every request; so their loyal readers are left to stew in the perpetual darkness of uncertainty.
The Solution
What if there was a way to...
1. read all of the articles
2. collect the text of the profiles
3. translate the text into some standardized representation
4. then collect allll of the admissions chances from the HBS Guru relating to that text
5. model the relationships between the profiles text and the admissions chances
6. then finally make it instantly accessible to everyone?
🤔 🤔 🤔 🤔
As you probably guessed, there is a way to do this. If you combine some tools, make a few crude assumptions, and offer a couple of nights as sacrifice to the computer gods (the old and the new) it's totally possible.
&As you may have guessed, I happen to have spent many an evening doing just this. Drum Roll!
🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁🥁
I'm very pleased to present to you a rough (read: wildly inaccurate) distillation of the entirety of the admissions process for top MBA programs. Give it a whirl, let's talk about it.
MBA Profile
Enter your stats/demographics. Note that they are crude because the model is crude and isn't attempting to capture all of the dimensions/nuances that make you special and more interesting than 7 parameters.
Why Are These Predictions Soo Bad?
If you're wondering why you may have gotten some quirky, questionable, dubious, or unquestionably off-base predictions then these next few sections are for you.
Limited Data
As the link to Poets&Quants shows, there are maybe 50-60 articles and each of them have around 4 or 5 profiles included on them. In total that gives us between 200-300 samples to play with. However, each school has its own model, and not every applicant profile includes chances for each school. Thus, no one school model was trained with more than 150 samples. In fact some schools like Duke, Dartmouth, and UCLA had so few samples that I decided to exclude their models from this article (they were that bad). While there are 200+ samples total available, I got blocked from web scraping a few times and think my scraper may have hit a login screen at one point, I can't say with 100% certainty that every profile on the site was obtained.
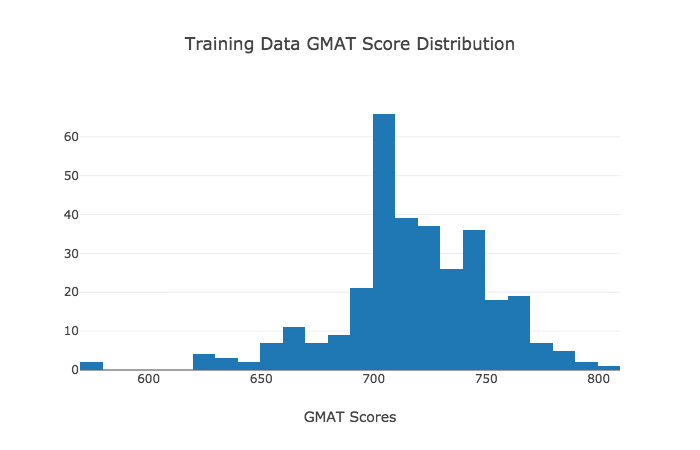
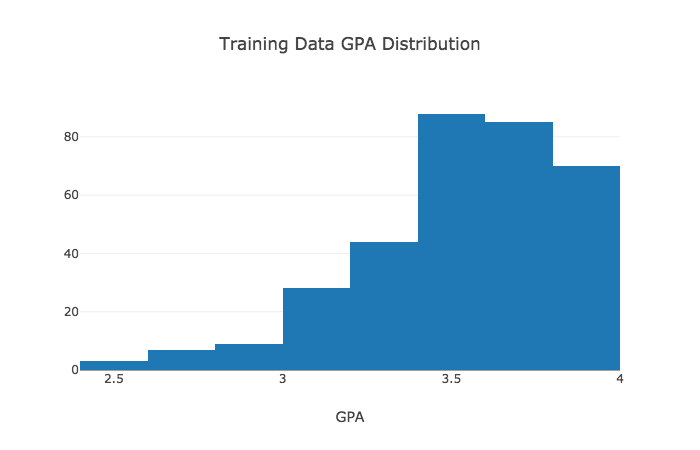
Additionally, a look at the data shows that most of the GPA's are between 3.0 - 4.0 and the GMAT scores are 600+. Thus, it should pretty much be expected that the model will perform poorly on inputs outside of these ranges because of the lack of exposure to similar examples.
Overfitting
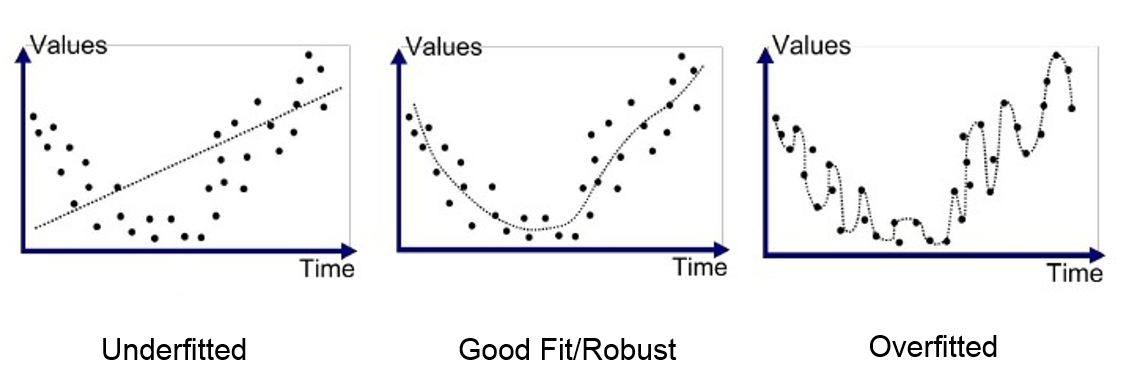
Closely related to the data issue, is the potential for overfitting. In any machine learning training process, you typically train on a subset of your data, say a random sample of 80% of all of your data. You then use the remaining 20% of the data to validate your model and check its "accuracy". I say accuracy in quotes here because there are many different types of evaluation metrics that one might use depending on the type of data and modeling you are doing. Overfitting occurs when you create a model that learns the training data sooo well, that it actually doesn't generalize to new data. Since our data was so limited I toyed around with using a pretty large percentage of it for training with varying degrees of success.
Poor Data Quality / Preprocessing
If you took a look at the articles in the Poets & Quants link you know that not every article presents the data in the same way, or even the same type of data for that matter. Some present GRE scores instead of GMAT scores, some times race isn't specified, other times nationality is specified instead, some applicants were educated internationally or went to M.I.T so have a GPA based on non 4.0 scale. And lastly, all of the data is provided as natural language, albeit somewhat structured through the use of a consistent page html structure.

So there was some elementary language processing with things like regular expressions and just matching on commonly used words. As a slightly smaller project I wrote a rough GRE -> GMAT converter to use in python for this project (its only a lookup table, with some fall back calculations for scores not explicitly in the table). It was used to convert instances of profiles that provide GRE scores and is now available for download on PyPi (a popular package manager for python libraries).
>>> from gre2gmat.conversions import gre2gmat
>>> gre2gmat(gre_verbal=170,gre_quant=160)
700
>>> gre2gmat(gre_verbal=170,gre_quant=161)
710
>>> gre2gmat(gre_verbal=170,gre_quant=162)
730
Unfortunately, not all data was formatted in this exact standard way and lots of edge cases proved too specific to create general rules for; thus many data points ended up making nooo sense. For instance one of my data points after preprocessing suggested that there was a 4 year old Asian male applying to Yale with an 800 GMAT, not entirely implausible but, unlikely. I did my best to throw out or manually correct samples like this, but no guarantees I got them all.
Lastly, categorical features, like race, major, university were originally encoded into multiple categories. In the early iterations of this model tried to do things with at least a semblance of granularity- Race had a separate value for Black, Latinx, White, Asian, Native American. Majors had a separate value for Engineering, Finance, Business, Economics, Philosophy, etc. Universities were categorized very crudely into 3 buckets, Tier 1, Tier 2, and Tier 3. After some trial and error I decided to make each of these binary. Race became Underrepresented minority (URM) or nah, Majors became STEM or Something Boring, Universities became "Ivy League"/Equivalents or Everyone Else. Unfortunately these mapping could have not been accurately done and more importantly are too low of resolution to capture the important nuances that are present in real life. However, this is one of the many tradeoffs you have to deal with when working with limited data sets.
With all that being said, you can see how some (or all) of these factors could have negatively impacted the overall model performance.
Ignoring Critical Features
Perhaps the most likely and important reason for a poorly performing model is an inability to select or engineer the correct features. Anyone who has ever been interested in MBA programs knows of the highly touted "holistic" nature of the admissions process. There are many factors that play a role in real life applications but were not used as inputs to the model (many of which aren't even included in the Poets & Quants articles). A non-exhaustive list:
- essays/narrative/story/trajectory
- years of work experience
- level of community engagement
- professional career advancement
- brand of employer
- work industry
- additional degrees/certifications
- international status
- military
- lgbtqia+
Most of these were excluded for the simple reason that they were either too difficult/varied to encode as features into the model or they were not consistently included in each applicant profile.
Inconsistencies of "HBS Guru"
There's also the possibility that "HBS Guru" who writes the articles that served as the ground truth for the model is not providing consistent judgment / assessment of submitted profiles.
Actually Though...
Lastly, we have to think back to the actual raw source of data. A person, albeit an allegedly qualified person, is making their best guess at someone's chance of getting into an MBA program based off of limited data provided by readers of the column. In an ideal situation the ground truth from which the model was trained would be real MBA admissions data associated with full application packets. But, until that mythical dataset exists, we're stuck with things like this... Making a model that guesses your chances to get into business school based on data that is really just another person's guess at other people's chances to get into business school, based on data that probably doesn't even contain enough information to answer that question in real life... So, essentially it really is just a crapshoot.
And to zoom out some more, even the fancy people sitting at the admissions table are guessing about the potential of applicants to be successful based on the limited information provided in an application. And realllyyy if you think about it, getting an MBA is just a feature/signal that other employers/investors/interested parties use to guess at how smart/capable you are..
So what's the point? 🤔